Why AI Washing Survives Vendor Demos
- AI washing is the gap between demo conditions and production behavior, observable without a technical audit
- Three signals separate genuine AI from rule-based automation: edge case behavior, output explainability, and commitment reversibility
- AI washing compounds across your stack: one unwashed tool degrades every layer that reads from it
The demo worked. You know this.
The model was fast. The outputs looked clean. The attribution lined up. The vendor showed you your own data coming back smarter.
Then you deployed it.
AI washing is the gap between the demo and the deployment, and the filter that closes it doesn't require a technical audit, only three signals any practitioner can observe from the outside.
That gap has three observable sides. It's been sitting in your stack longer than you've had a name for it.
AI Washing Lives in the Gap Between Demo and Deployment
Vendor demos run on controlled conditions by design. Curated inputs. Pre-run inference. Data selected from your account that produces results worth showing. AI washing only becomes visible when you remove the conditions that made the demo work.
AI washing isn't always deliberate. It's the systematic distance between how AI is marketed and what you can observe once it's in production. Vendors often don't know their model performs differently once the curated conditions disappear.
The problem is that budget decisions happen during the demo. Not after six weeks in your live stack.
Three Signals AI Washing Consistently Fails
Genuine AI and rule-based automation with better UI look identical in a demo. They look different under three specific conditions.
Edge case behavior. Genuine AI degrades gracefully when pushed outside its training envelope. Automation breaks hard: it returns a confident wrong answer, errors out, or collapses to a default that ignores the actual context. Test this deliberately: feed the tool an unusual input, something the demo never touched. Watch how it fails. The failure mode is the signal.
Vendors say their system adapts to real-world data. What adapts is the error message.
Explainability of outputs. Genuine AI can surface why a recommendation was made. "The model weighted recency over historical conversion patterns" is an explanation. "Our proprietary algorithm determined the optimal bid" is not. Davenport and Miller, in Working with AI (2022), identified explainability as the practitioner-observable signal that requires no technical audit: if the tool cannot show its reasoning, the reasoning isn't there.
Vendors say transparency is a priority. What they show you is a dashboard, not a decision tree.
Commitment reversibility. If your historical data exists only inside their system, switching off the tool means losing institutional knowledge. The AI is a data format with a monthly fee. Genuine AI tools should be replaceable. Their value is in the model output, not in the switching cost built around your data.
Vendors say they are partners in your success. What they mean is that leaving is expensive.
If the tool cannot show its reasoning, the reasoning isn't there.
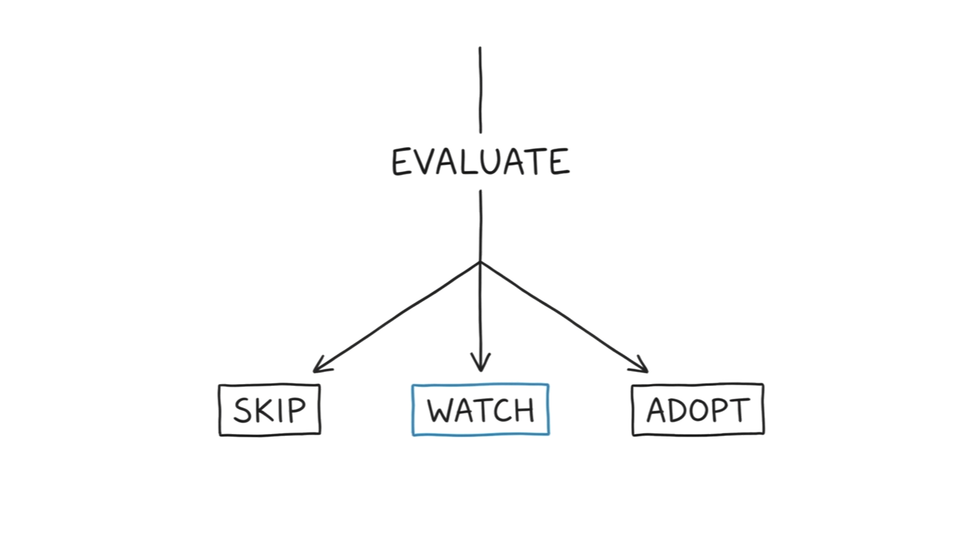
AI Washing Filter Returns Three States, Not Two
Every vendor evaluation guide on the SERP returns a binary: pass or fail, buy or don't buy. That frame works for enterprise procurement. It fails the practitioner making a judgment call inside an existing stack.
The AI washing filter returns three states. Mike King's GEO agency selection framework uses the same gradient logic: real signals versus red flags, without a binary gate.
Skip: two or more signals fail. The tool breaks on edge cases, cannot explain its outputs, and makes switching expensive. This is AI washing. Do not adopt.
Adopt: all three signals pass under controlled observation. The tool degrades gracefully, surfaces its reasoning, and holds its value without holding your data hostage. Proceed with integration.
Watch: signals are mixed. One passes, one fails, one is inconclusive. Do not commit budget. Run a controlled deployment: 30 days, defined scope, explicit exit criteria. Decide after observation, not after the pitch.
Watch is the state the SERP never offers. Binary evaluation forces a premature decision. The Watch state protects the budget while evidence accumulates.
AI Washing Compounds When You Don't Filter Early
If every tool in your attribution stack carries an AI washing rate, what does your attribution model actually represent?
Each layer reads from the layer below it. Attribution reads from analytics. Analytics reads from tagging. Bidding reads from attribution. An unwashed tool at one layer doesn't fail in isolation. AI washing introduces noise into every downstream signal that reads from it.
CoSchedule's 2026 research found 79% of marketers say AI improved how they work, while major channel ROI declined across the same period. The gap between felt performance and measured performance is partly a tool quality problem. Building AI skills for marketers compounds only when the tools those skills run on produce real signal.
AI washing in one layer makes every layer above it less reliable. The stack confidently optimizes toward the wrong signal. The filter matters early not because one bad tool is catastrophic, but because one unwashed tool means the stack is performing correctly on bad data.
You don't need an ML engineering degree to catch AI washing.
You need three signals and controlled observation. You already have access to the edge case. You can ask for the output logic. You can read the contract for data portability.
You've been allowed to use these all along.